Why I Treat Chunking as a Product Decision
My goal here is not to restate textbook definitions. I care about shortening the path between idea and shipped system. I care about improving retrieval quality without burning cycles on the wrong layer of the stack. Chunking sits at that inflection point. It looks like an implementation detail, yet it quietly shapes user trust, answer accuracy, and infrastructure cost.
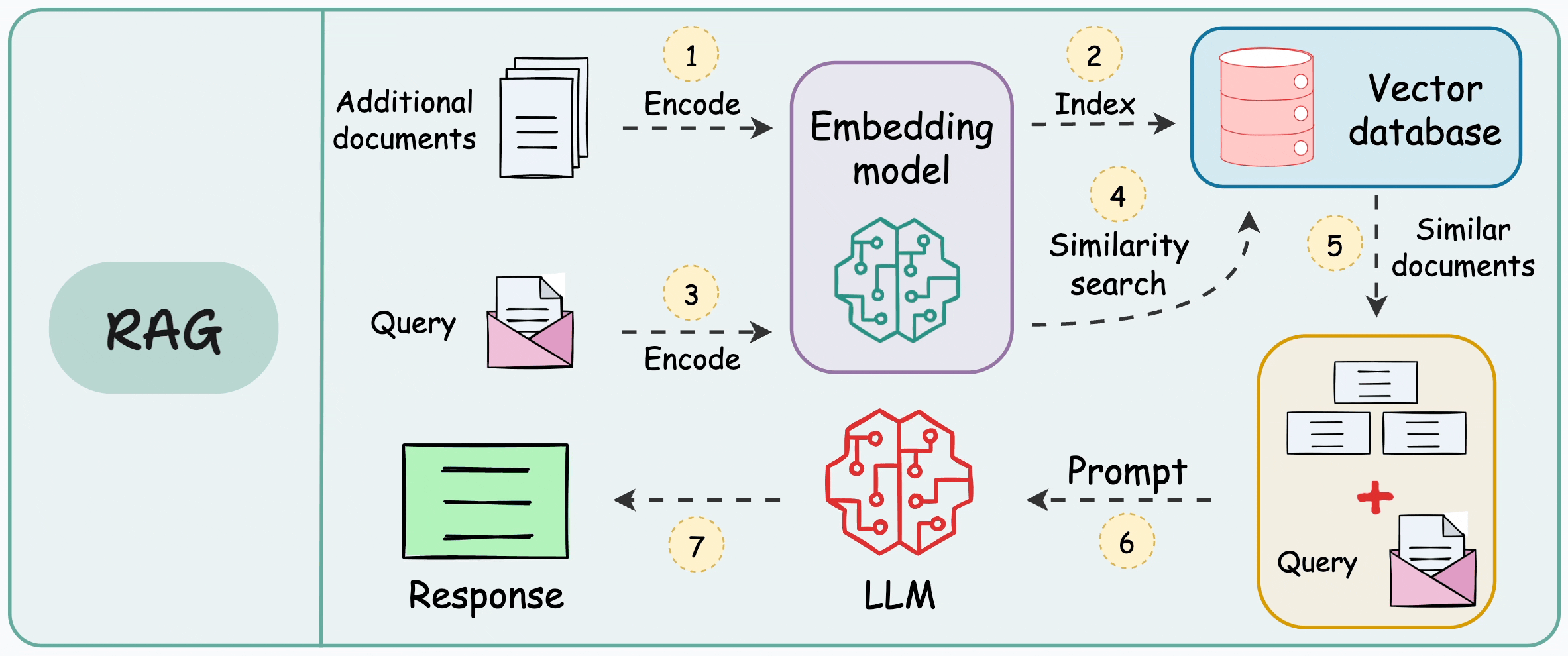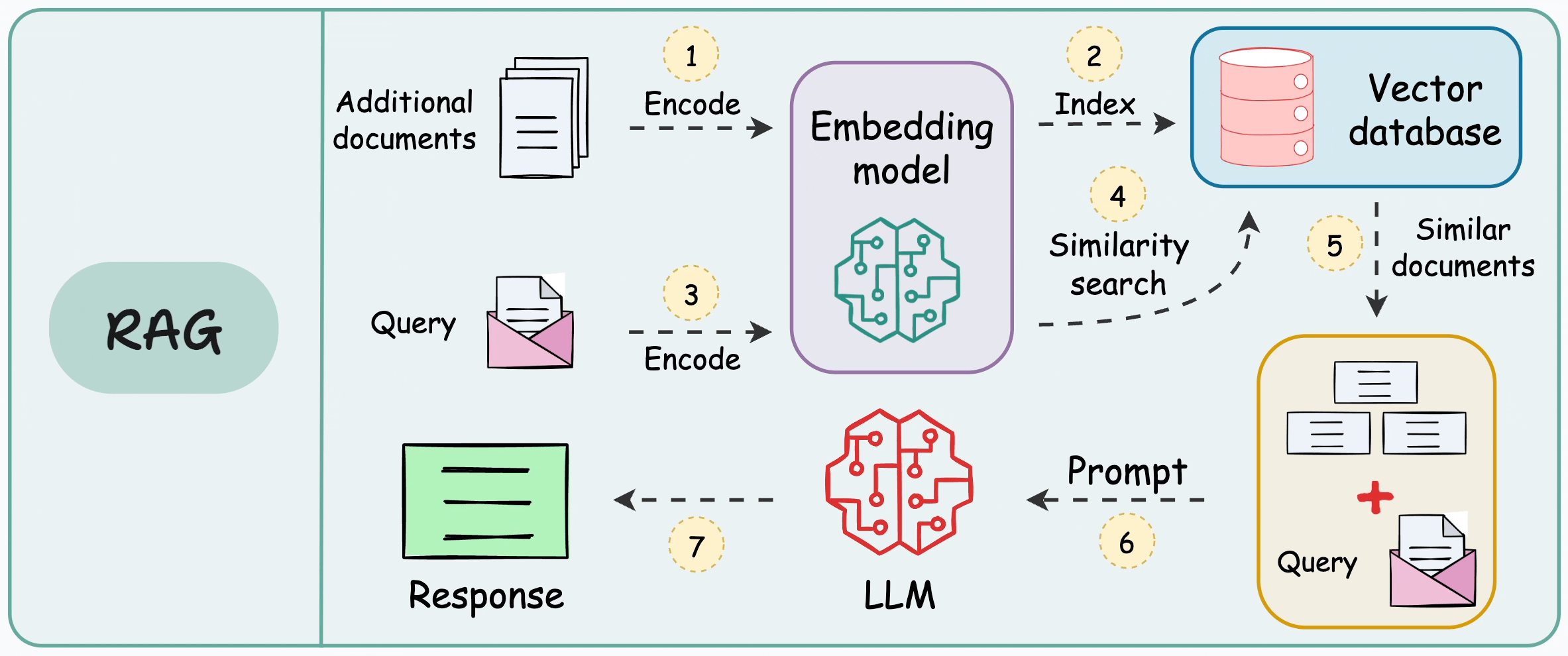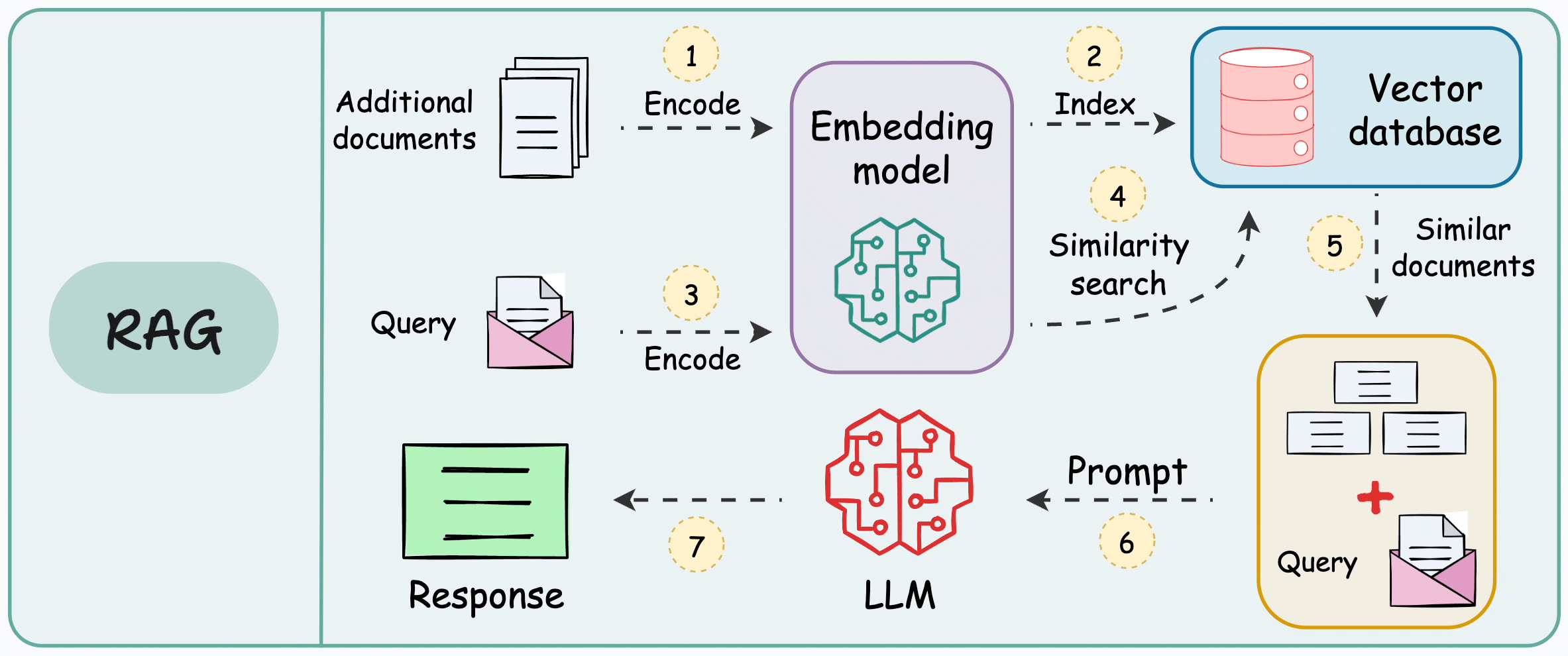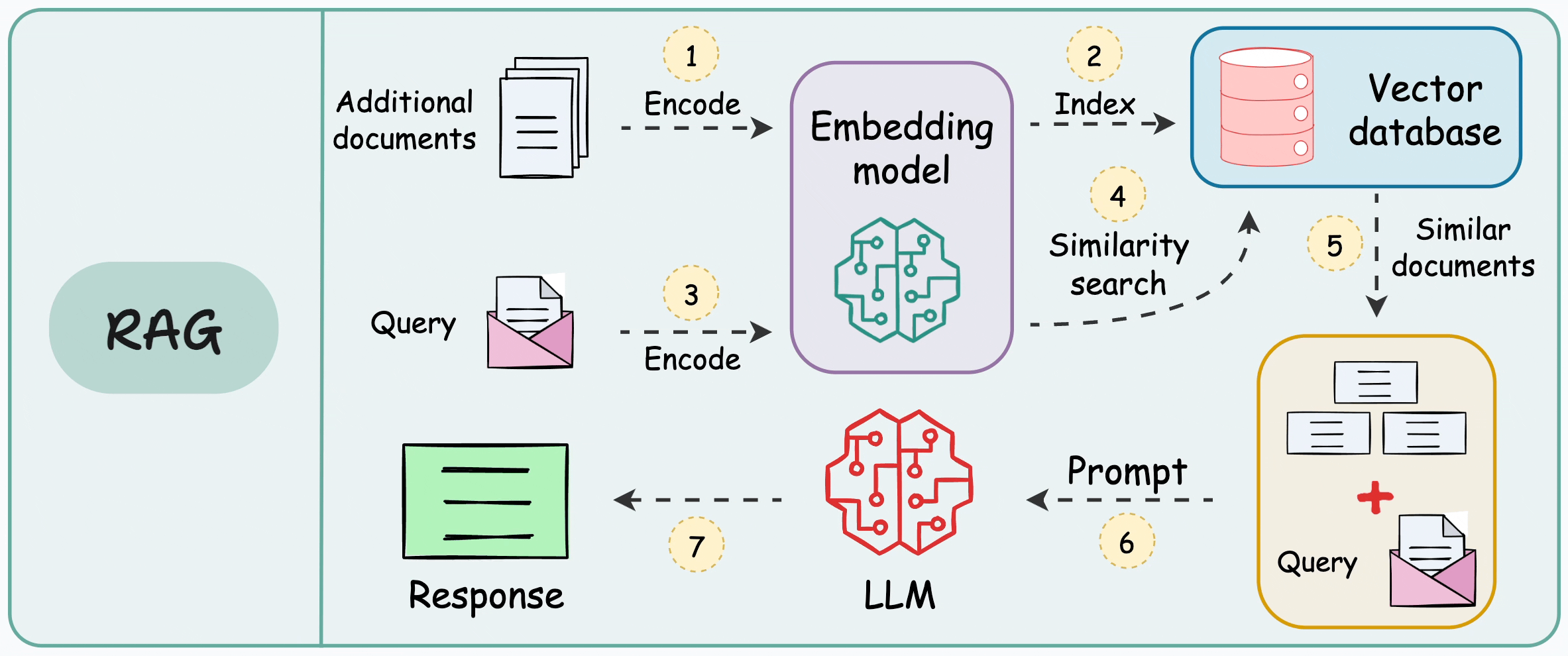
When we design a RAG system, chunking becomes one of the earliest product decisions we lock in. It determines what the retriever is even allowed to see. It shapes how much irrelevant context gets injected into the prompt. It influences whether the final answer feels grounded or vaguely stitched together. If chunking is weak, prompt engineering becomes cosmetic. We end up tuning wording instead of fixing the data substrate.
I frame chunking as a three way tradeoff between quality, speed, and cost. Every product surface sits somewhere different on that triangle. An internal search tool for ops teams can tolerate occasional fuzziness. A customer facing compliance copilot cannot afford to cite the wrong paragraph. The chunking strategy has to reflect that risk profile.
Fixed size chunking
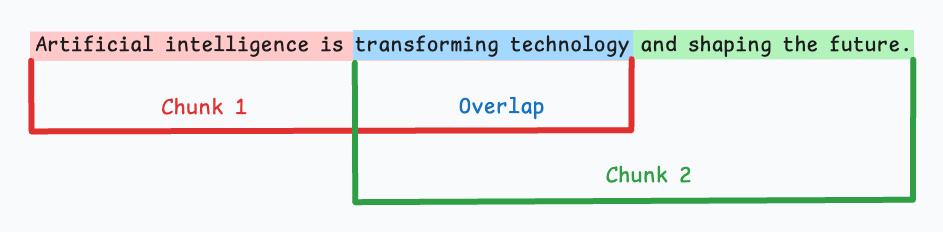
Fixed size chunking is where I start when we need a baseline fast. We divide documents into equal token windows with light overlap to preserve continuity. It is operationally simple. Indexing time is predictable. Scaling is straightforward. Engineering effort is minimal, which matters in early validation.

The cost shows up in semantic fractures. A definition may start at the end of one chunk and conclude at the beginning of the next. Retrieval then returns partial thoughts. The model receives context that looks complete structurally but is incomplete logically. Precision drops in subtle ways. The answer is not obviously wrong, but it feels thin.
In early stage systems, I typically operate in the 400 to 800 token range with 10 to 20 percent overlap. That range balances embedding efficiency with contextual integrity. It is rarely optimal, but it is good enough to generate signal and expose real query patterns.
Semantic chunking
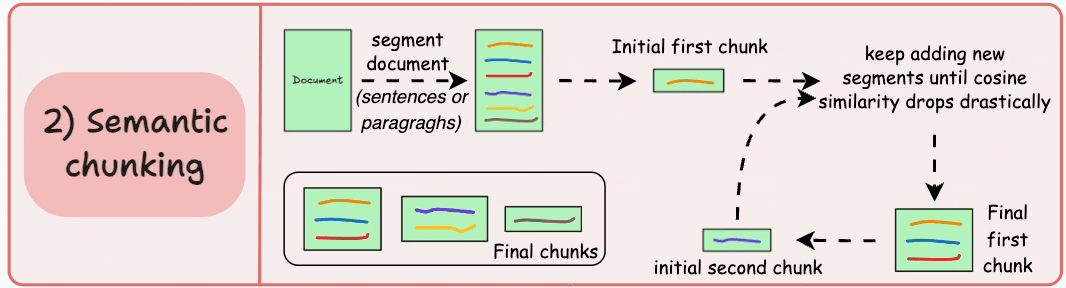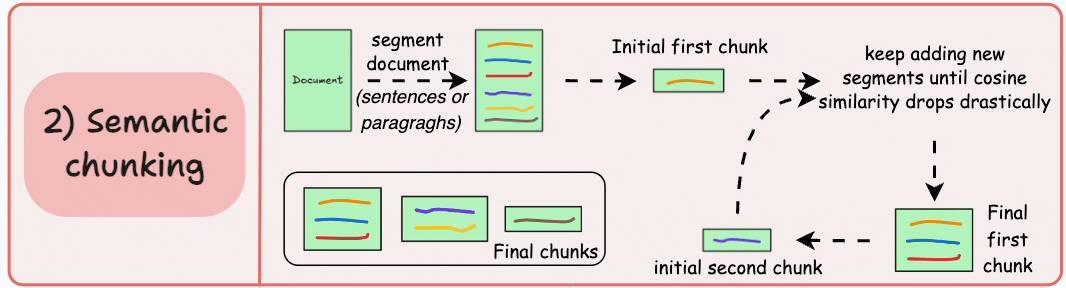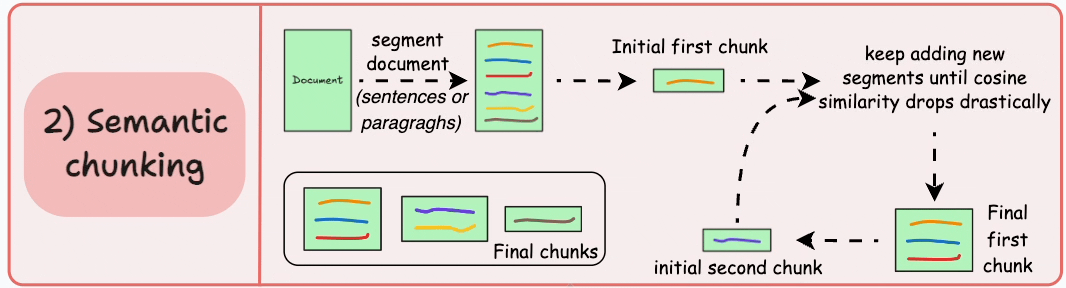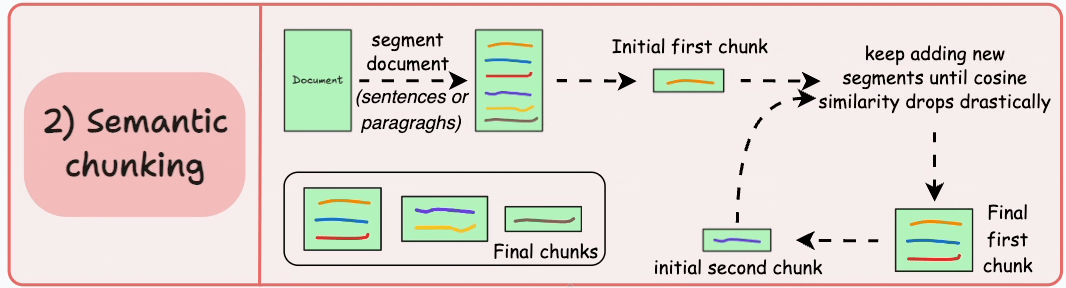
Semantic chunking treats text as meaning first and tokens second. We begin from sentences or paragraphs and merge neighboring units based on embedding similarity. Instead of cutting by length, we cut by coherence.
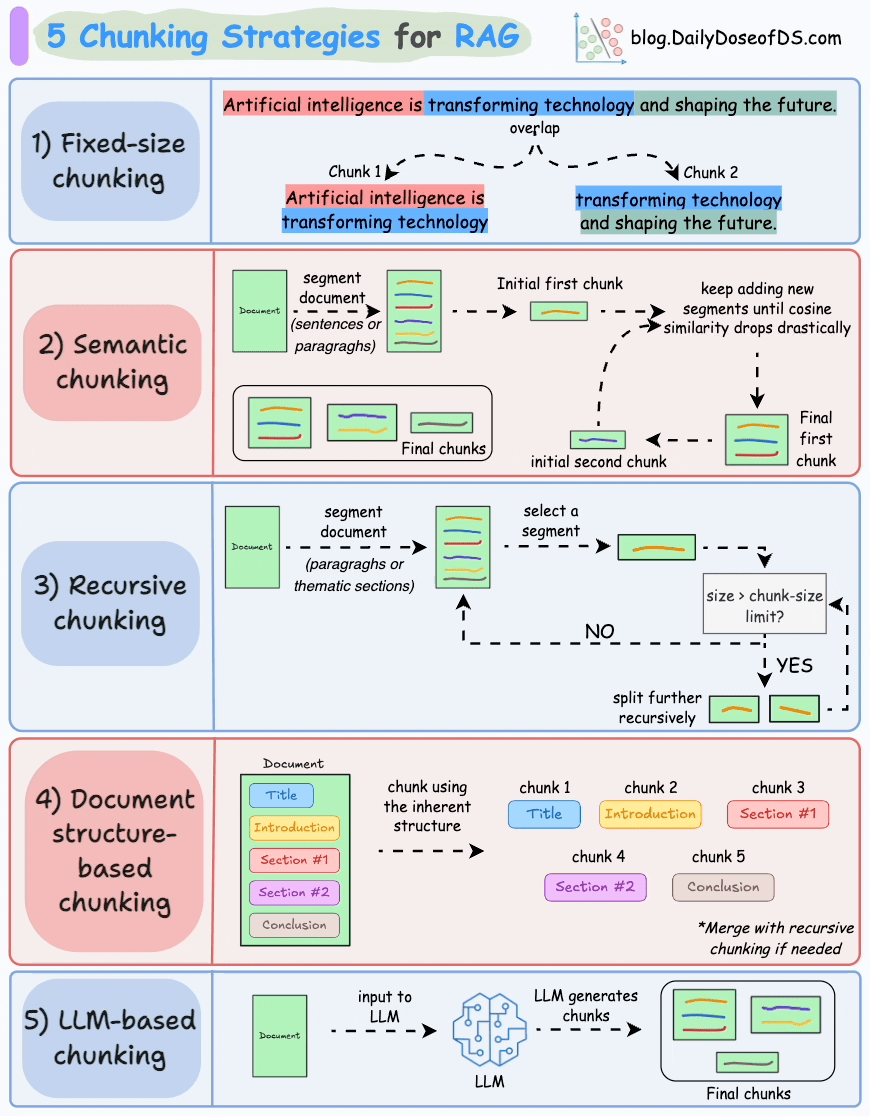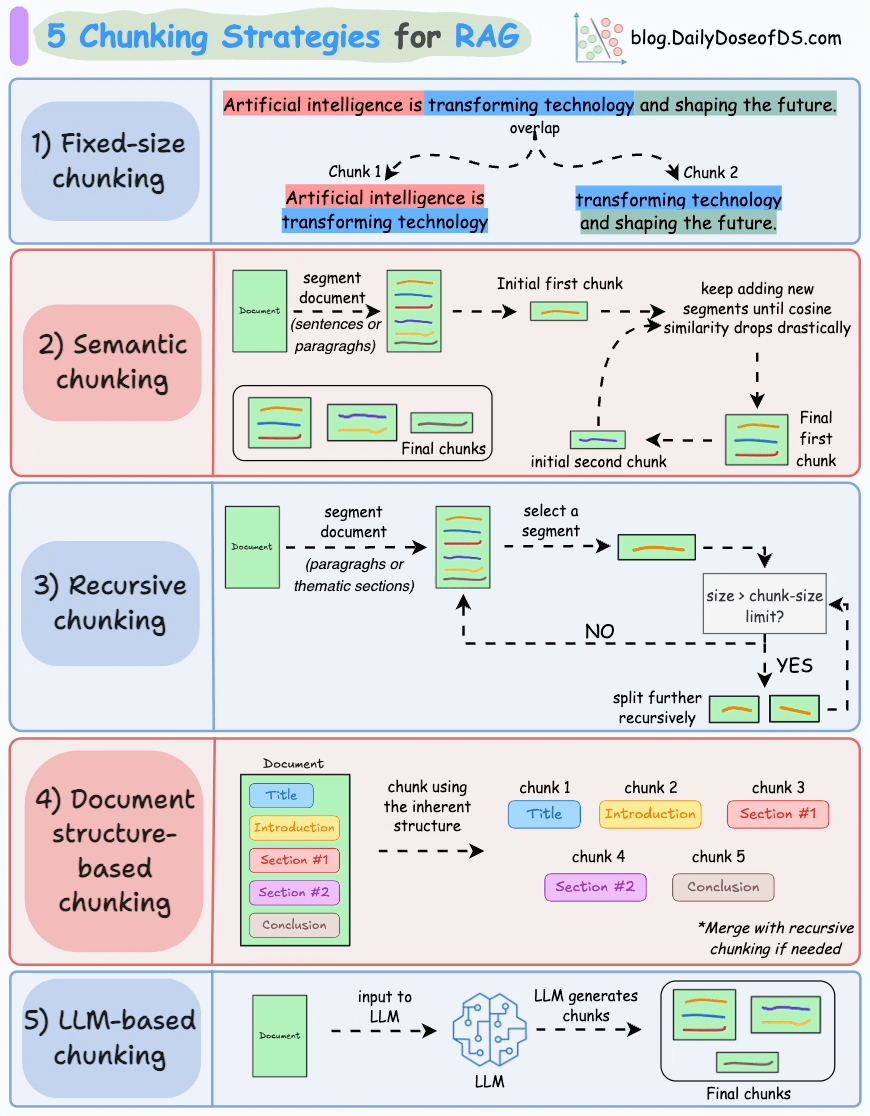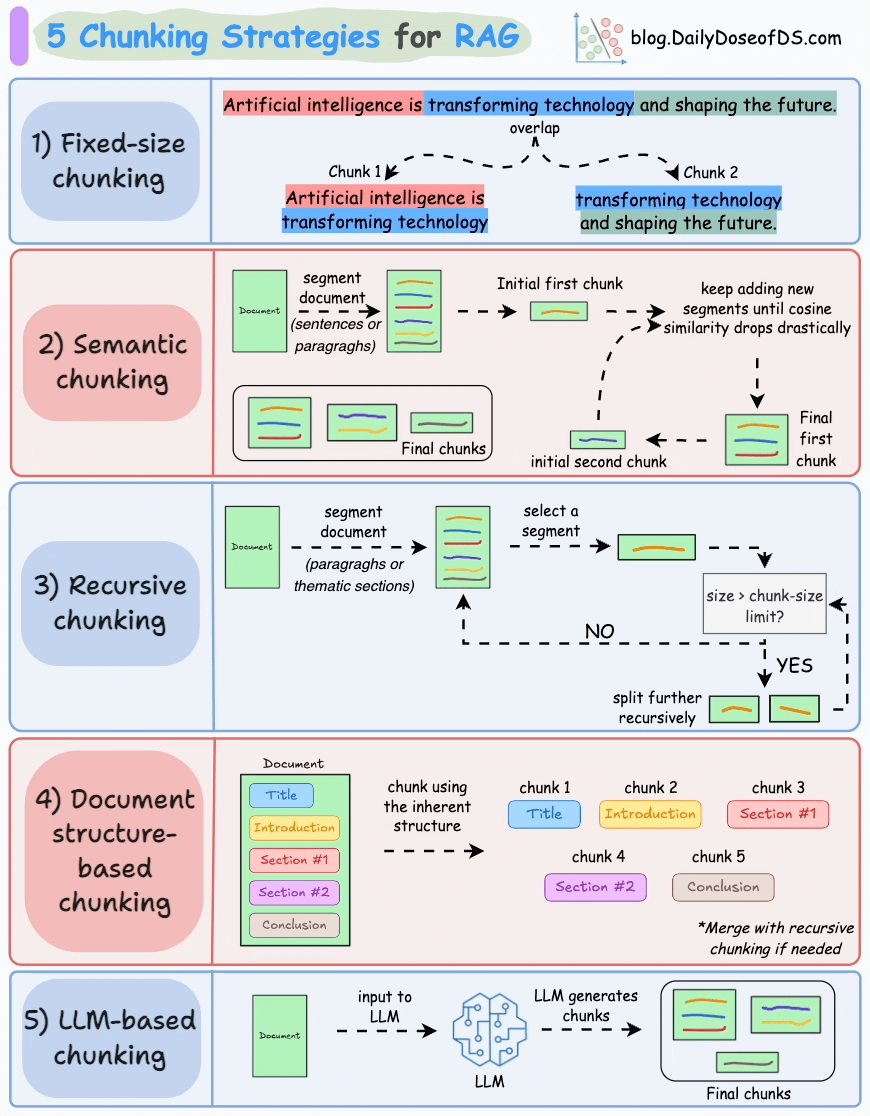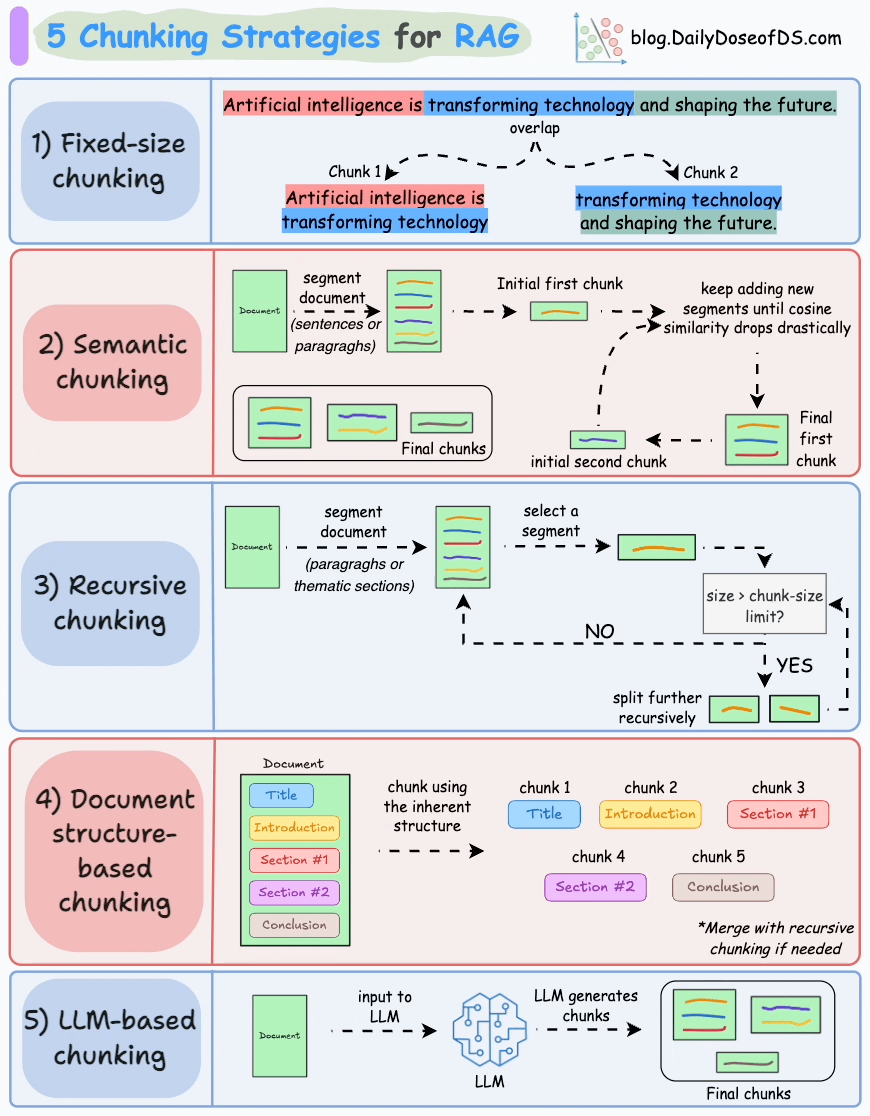
I lean on this approach when boundary errors are expensive. Policy documents, technical specifications, and dense knowledge bases benefit from preserving complete thoughts. When a user asks for a specific clause, returning an intact conceptual unit dramatically improves groundedness.
The operational challenge is threshold tuning. Merge too aggressively and chunks become bloated with loosely related material. Be too strict and we fragment context, forcing the retriever to work harder to reconstruct intent. I do not tune this by intuition. I tune it against retrieval metrics and real query logs. If Recall@k improves but citation fidelity drops, I know we merged too far.
Semantic chunking is not just an algorithmic decision. It is a quality investment. It increases ingestion complexity and compute cost, so I reserve it for corpora where coherence materially affects user trust.
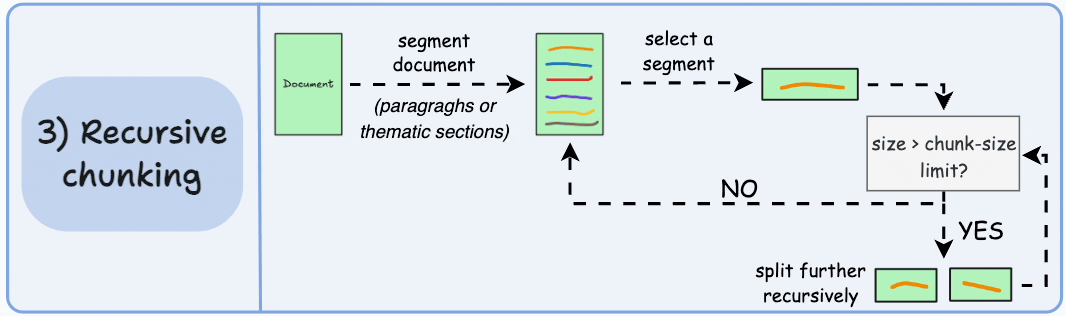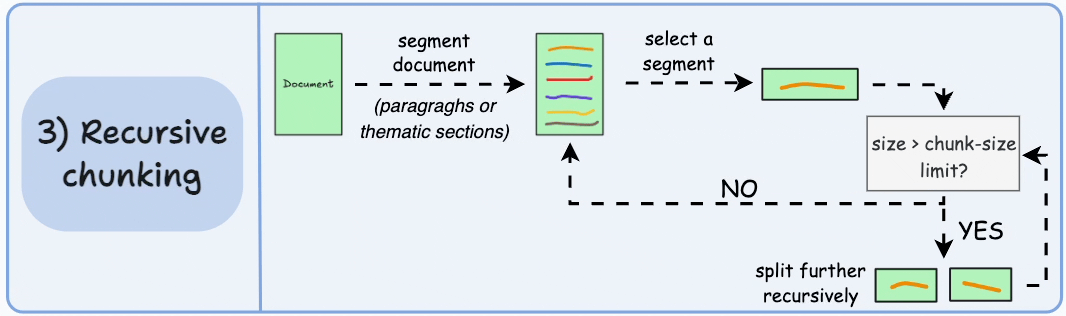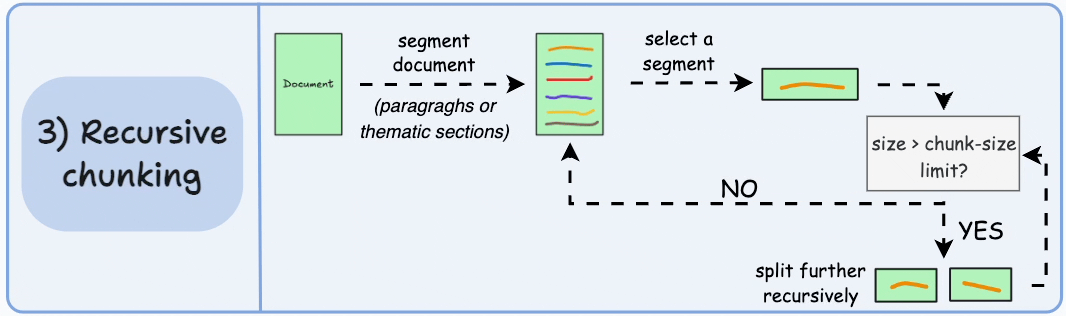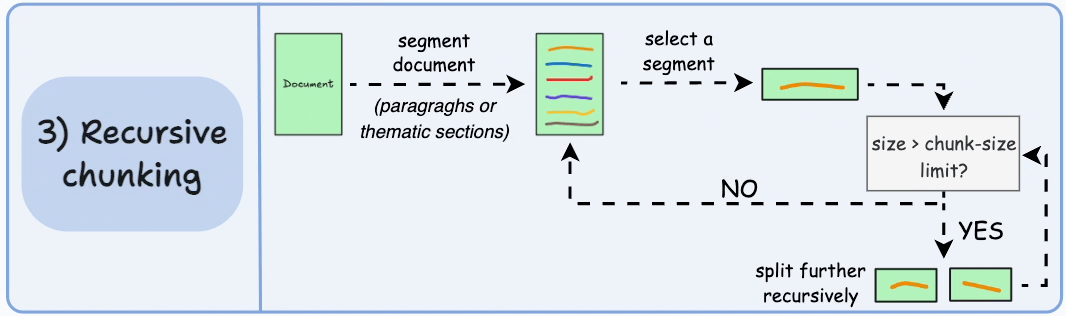
Recursive chunking
Recursive chunking is my default production baseline for heterogeneous corpora. We split first by high signal separators such as headings or paragraph breaks. If a segment exceeds token limits, we split again using a lower level boundary. We continue until every piece fits our constraints.
This layered approach respects structure without assuming it is clean. It adapts to long reports, short memos, and semi structured documentation with minimal special casing. In practice, it gives us a strong quality to effort ratio. We preserve more logical grouping than fixed windows while avoiding the full computational overhead of semantic clustering.
From a roadmap perspective, recursive chunking is often the fastest path to stable retrieval behavior. It creates a reliable floor of quality that we can iterate on with instrumentation.
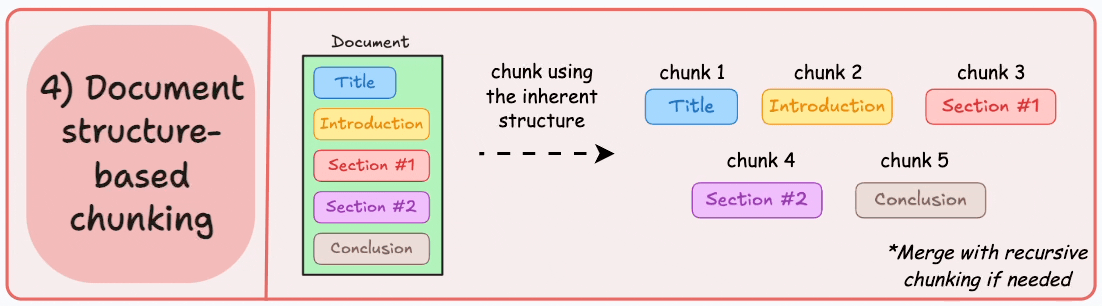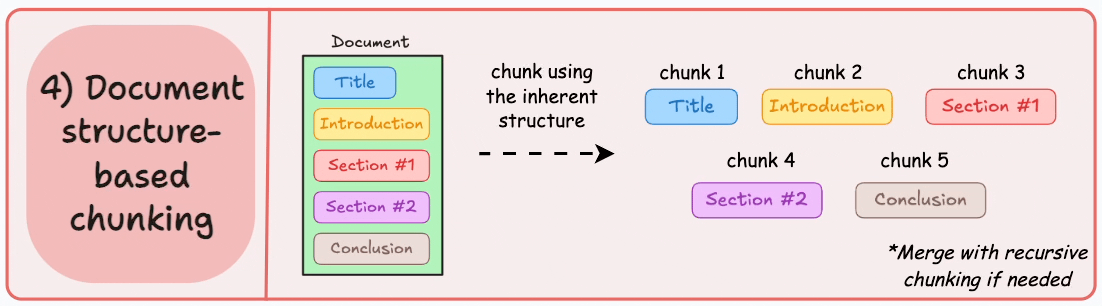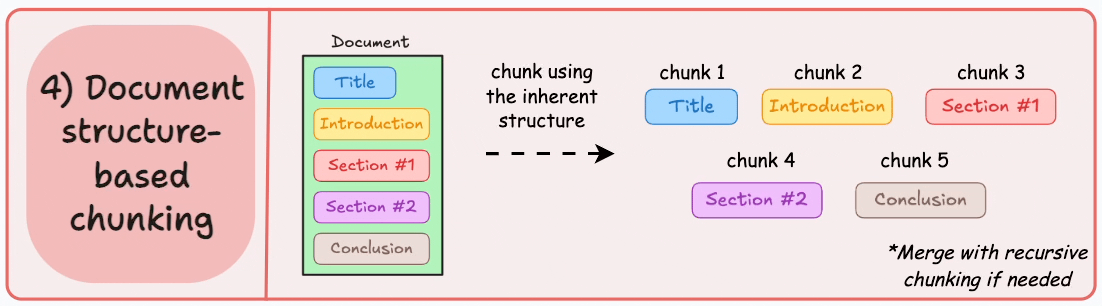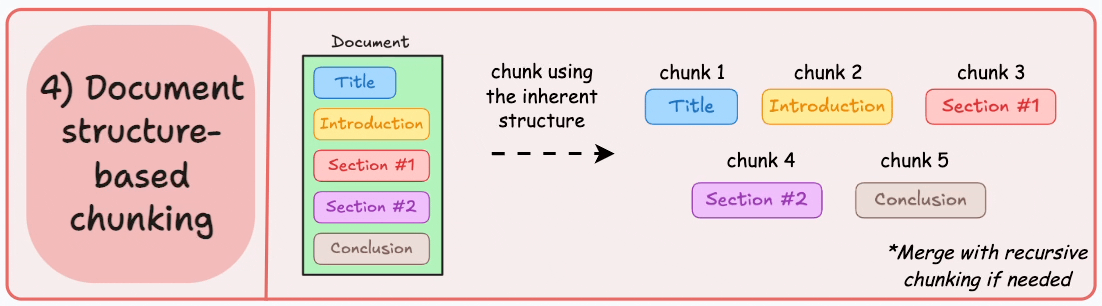
Structure based chunking
Structure based chunking follows explicit hierarchies such as headings, sections, lists, and tables. When documents are well formatted, this strategy improves explainability immediately. We can point to a section title and show users exactly where the answer originated.
I prefer this approach for handbooks, standard operating procedures, legal documents, and product requirement specs. These are environments where traceability is as important as correctness. When a compliance team asks why the model responded a certain way, section aligned chunks make that conversation defensible.
The constraint is real world messiness. Not every corpus has consistent formatting. Markdown may be clean while PDFs are chaotic. In those cases, I layer structure awareness on top of recursive fallback logic. Product quality should not depend on perfect authoring hygiene.
LLM based chunking
LLM based chunking delegates boundary decisions to a model. We ask it to segment documents into semantically complete units, often with instructions about granularity or topic shifts. The quality can be impressive, particularly for nuanced material where rule based heuristics fail.
I treat this as a targeted investment. Ingestion latency increases. Costs scale with corpus size. Operational complexity grows because we now depend on model behavior during preprocessing, not just during generation.
From a product management standpoint, I scope LLM chunking to high value domains where wrong answers carry meaningful risk. For example, regulatory guidance or revenue critical product documentation. I do not default the entire knowledge base to this method without evidence that simpler strategies are insufficient.
How I choose in production
In practice, I sequence decisions rather than debate them in abstraction. I begin with recursive chunking and lightweight overlap to establish a performance baseline. I instrument retrieval from day one so we can observe Recall@k, ranking distribution, and answer level citation patterns.

If we detect precision issues tied to noisy boundaries, I introduce structure awareness where formatting is reliable. If certain document classes continue to underperform, I selectively apply semantic chunking and measure uplift. Only when those levers plateau do I consider LLM based segmentation for the highest risk surfaces.
This progression keeps effort proportional to impact. It also aligns with how teams secure budget. Demonstrated gains justify deeper investment.
My rollout approach
When I operationalize this in a roadmap, I phase it deliberately.
Phase one focuses on baseline reliability. We implement recursive chunking, capture rich metadata, and build retrieval dashboards.

| Phase | Objective | Chunking Strategy | Success Criteria |
|---|---|---|---|
| Phase 1 | Reliability | Recursive + overlap | Stable Recall@k, traceable citations |
| Phase 2 | Quality uplift | Structure aware + selective semantic | Improved ranking quality without latency regression |
| Phase 3 | Premium precision | Targeted LLM chunking | Measurable groundedness gains in high risk flows |
At this stage, I care more about observability than perfection.
Phase two targets quality uplift. We introduce structure aware boundaries for clean document sets and experiment with semantic grouping in noisy domains. Every change is evaluated against offline benchmarks and live traffic slices.
Phase three is premium quality. We apply LLM based chunking selectively to segments where answer risk is highest and business impact justifies the cost. By this stage, we are not guessing. We are optimizing a system we understand.
Strategy comparison at a glance

| Strategy | Quality Potential | Cost Profile | Latency Impact | Best For | My Default Stance |
|---|---|---|---|---|---|
| Fixed size | Moderate | Low | Low | Fast prototyping | Baseline only |
| Recursive | High | Low to Moderate | Low | Mixed corpora | Production default |
| Structure based | High when formatting is clean | Low | Low | SOPs, legal, specs | Layer on top of recursive |
| Semantic | High in dense knowledge domains | Moderate | Moderate | Policies, technical docs | Targeted by document class |
| Hierarchical | Very High | Moderate | Moderate | Large structured corpora | For mature systems |
| Late chunking | High with storage efficiency | Low to Moderate | Moderate at query time | Large scale retrieval | Cost optimization lever |
| LLM based | Very High in nuanced domains | High | High | High risk knowledge surfaces | Premium tier only |
Product framing: I do not ask which method is theoretically best. I ask which method improves Recall@k and groundedness per dollar and per millisecond.
What I track
I evaluate chunking through retrieval behavior and groundedness outcomes. Recall@k tells me whether relevant information is even reachable. Ranking metrics reveal whether the right chunks surface near the top. Citation fidelity in final answers shows whether generation is anchored to the retrieved text or drifting beyond it.

When generation quality drops, I inspect chunk boundaries before touching the model. It is tempting to upgrade to a larger model or tweak prompts. Often the real issue is that the retriever never received a coherent unit of meaning. That discipline prevents us from solving the wrong layer of the stack.
Emerging strategies in 2026
Over the past year, I have seen chunking evolve from a preprocessing tactic into a dynamic retrieval design layer. Production systems increasingly move beyond single strategy pipelines and adopt adaptive segmentation depending on corpus type, query intent, and risk tier.
One shift I take seriously is late chunking. Instead of pre splitting every document into small pieces at ingestion time, we first retrieve at a broader document or page level and only then segment the most relevant candidates. This reduces index size, preserves cross section relationships, and avoids fragmenting content that may never be queried. In high volume systems, this can materially lower storage and embedding cost while improving contextual integrity.
Another pattern gaining traction is hierarchical segmentation. We embed both fine grained segments and higher level clusters such as sections or grouped subsections. Retrieval can operate at multiple levels, pulling a precise paragraph while also referencing its parent section for global framing. In practice, this reduces the common failure mode where a highly specific chunk is retrieved without sufficient surrounding context to answer confidently.
Intent aware chunking is also emerging in more mature stacks. By analyzing historical query logs, we identify dominant question types and reshape chunk boundaries around those intents. If users frequently ask for procedural steps, we ensure steps are preserved as atomic units. If they ask for definitions, we bias segmentation toward definitional completeness. Chunking becomes informed by user behavior rather than static heuristics.
On the post retrieval side, LLM based chunk filtering is becoming standard in high risk systems. Instead of passing the top k retrieved chunks directly into generation, we apply a semantic relevance filter that scores and prunes marginal content. This tightens grounding and reduces hallucinated synthesis across weakly related segments. It effectively treats retrieval as a two stage ranking problem.
For specialized domains such as code, we increasingly see structure aware chunking based on abstract syntax trees. Functions, classes, and modules become first class retrieval units. This preserves logical integrity and dramatically improves downstream code generation and explanation quality.
Importantly, recent empirical evaluations show that semantic chunking does not universally outperform simpler recursive or hybrid strategies. Gains are corpus dependent. This reinforces my bias toward instrumentation before sophistication. We should earn complexity with measurable uplift.
What I track
I evaluate chunking through retrieval behavior and groundedness outcomes. Recall@k tells me whether relevant information is reachable. Ranking metrics show whether the right chunks surface near the top. I examine citation fidelity in final answers to verify that generation remains anchored to retrieved text rather than drifting.
I also monitor chunk size distribution, overlap redundancy, embedding volume growth, and latency impact. If retrieval improves but latency doubles, that is not a net product win. If groundedness improves but index size explodes, we need to reassess scope.
When answer quality drops, I inspect chunk boundaries before changing models or prompts. Many generation issues originate from incoherent segmentation upstream. This discipline keeps us from optimizing the wrong layer.
Closing
There is no universally superior chunking strategy. The correct choice depends on corpus structure, query distribution, latency budget, and business risk. As a Technical AI PM, I treat chunking as a controllable product surface that evolves with evidence.
We instrument early. We adapt by document class and intent. We layer sophistication only when metrics justify it. In mature RAG systems, chunking is not static preprocessing. It is an active lever that shapes retrieval quality, cost profile, and ultimately user trust.